Or: Why is this software engineer being so difficult?
So you’ve got some data. In my case, I’ve been keeping track of how successful my taco truck has been.
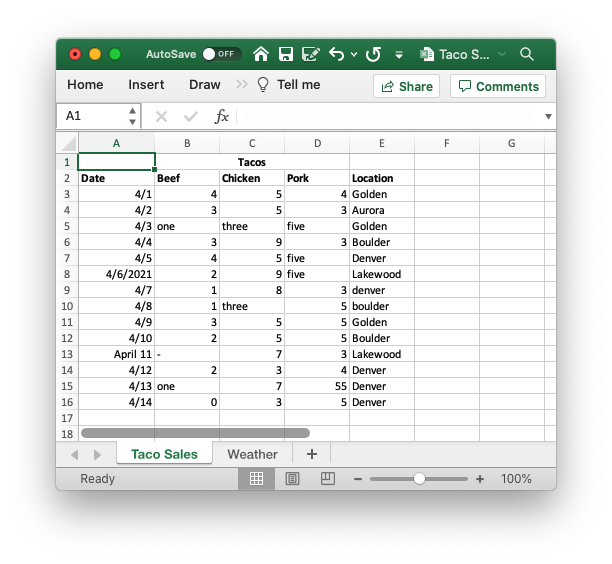
There’s nothing crazy here: a date column, how many of each kind of taco I sold, and where I parked my taco truck that day. At this point, I’d like to create some sweet visualizations of my data, to better understand the fundamentals of my taco truck business. I know a little python, and I’ve heard it’s good at this kind of thing, so I fire up a jupyter notebook and import it into a pandas dataframe.
import pandas as pd
from matplotlib import cm
pd.options.display.max_rows = 7
df = pd.read_excel('./versions/Taco Sales - v1.xlsx')
df.head()
Wow, that’s not what I was expecting.
Leaving aside the column headings, those dates aren’t what I’m seeing in Excel at all!
The usual solution to problems like this is “plain text”, but Excel files don’t work like that at all. Luckily, they can be converted to “csv”s, or Comma Separated Values, which are plain text, and can be viewed in a text editor to make sure your data is exactly what you expect it to be. To convert, click “save as” and then pick “CSV” from the list of dropdown options. You end up with something you can open in TextEdit that looks like this:
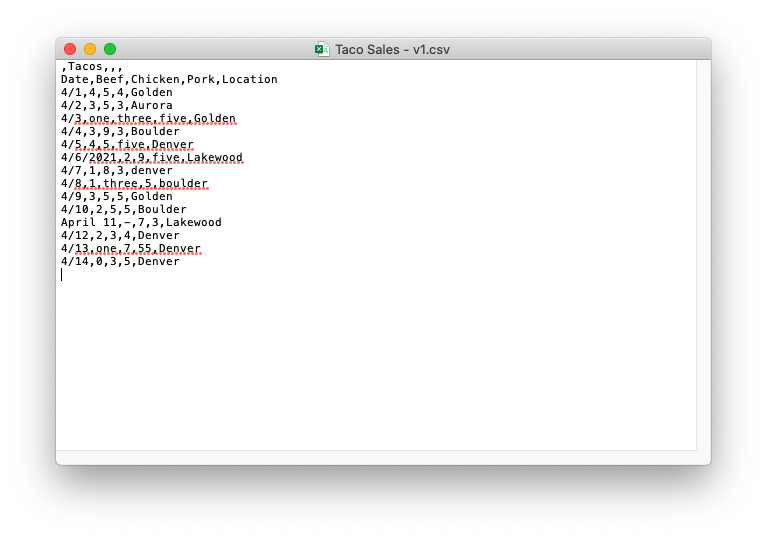
Not exactly the most readable thing in the world, but at least you can see exactly what your data looks like.
Let’s re-import that into pandas.
df = pd.read_csv('./versions/Taco Sales - v1.csv')
df.head()
That matches what we see in TextEdit, great!
Now, that tacos row isn’t doing us any favors. Pandas is trying to use it as the “header row”, but the only useful piece of information in it is the word “tacos”, and it’s pushing our actual column labels into our data. Let’s delete that.
df = pd.read_csv('./versions/Taco Sales - v2.csv', index_col='Date')
df
Now we’re cooking! I think we’re ready to plot our sales…
df[['Beef', 'Chicken', 'Pork']].plot(colormap=cm.Paired)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-6894eca31d4b> in <module>
----> 1 df[['Beef', 'Chicken', 'Pork']].plot(colormap=cm.Paired)
~/Documents/notebooks/.venv/lib/python3.8/site-packages/pandas/plotting/_core.py in __call__(self, *args, **kwargs)
953 data.columns = label_name
954
--> 955 return plot_backend.plot(data, kind=kind, **kwargs)
956
957 __call__.__doc__ = __doc__
~/Documents/notebooks/.venv/lib/python3.8/site-packages/pandas/plotting/_matplotlib/__init__.py in plot(data, kind, **kwargs)
59 kwargs["ax"] = getattr(ax, "left_ax", ax)
60 plot_obj = PLOT_CLASSES[kind](data, **kwargs)
---> 61 plot_obj.generate()
62 plot_obj.draw()
63 return plot_obj.result
~/Documents/notebooks/.venv/lib/python3.8/site-packages/pandas/plotting/_matplotlib/core.py in generate(self)
276 def generate(self):
277 self._args_adjust()
--> 278 self._compute_plot_data()
279 self._setup_subplots()
280 self._make_plot()
~/Documents/notebooks/.venv/lib/python3.8/site-packages/pandas/plotting/_matplotlib/core.py in _compute_plot_data(self)
439 # no non-numeric frames or series allowed
440 if is_empty:
--> 441 raise TypeError("no numeric data to plot")
442
443 self.data = numeric_data.apply(self._convert_to_ndarray)
TypeError: no numeric data to plot
Oh no!
If we google this error message, we find a pandas function to_numeric that might help us, but as you can see, that has its own problems.
df['Beef'] = pd.to_numeric(df['Beef'], errors='coerce')
df['Chicken'] = pd.to_numeric(df['Chicken'], errors='coerce')
df['Pork'] = pd.to_numeric(df['Pork'], errors='coerce')
df[['Beef', 'Chicken', 'Pork']].plot(colormap=cm.Paired)
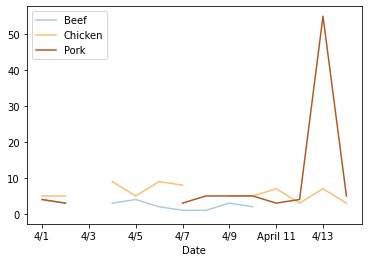
Our chart has holes in it!
The only way to fix this is to back to the source and make sure that we consistently write our numbers as numbers, and not as their English equivalent: "1", not "one". "0", not "-"!
df = pd.read_csv('./versions/Taco Sales - v3.csv', index_col='Date')
df[['Beef', 'Chicken', 'Pork']].plot(colormap=cm.Paired)
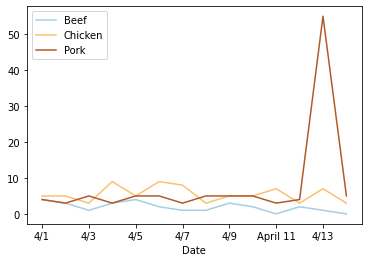
And we should probably do something similar to the Date column so that we don’t see that random “April 11”.
df = pd.read_csv('./versions/Taco Sales - v4.csv', index_col='Date')
df[['Beef', 'Chicken', 'Pork']].plot(colormap=cm.Paired)
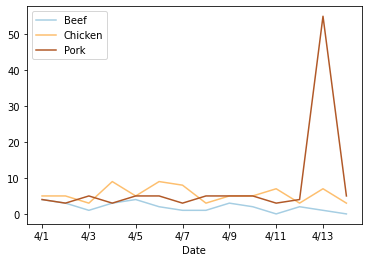
There’s a weird spike on the 13th, but we’ll come back to that later.
Now that I’m tracking how much I’m selling, it would be nice to know where I’m spending most of my time.
df['Location'].value_counts().plot(kind='bar', colormap=cm.Paired)
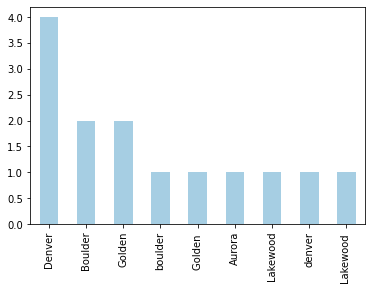
Well, that’s not helpful. Most of these cities are in there twice!
df['Location'].unique()
array(['Golden', 'Aurora', 'Golden ', 'Boulder', 'Denver', 'Lakewood ',
'denver', 'boulder', 'Lakewood'], dtype=object)
The problem is that these values are not exactly the same. Inconsistent casing or extra spaces make pandas treat them as separate labels.
This is another thing we need to clean up first.
df = pd.read_csv('./versions/Taco Sales - v5.csv', index_col='Date')
df['Location'].unique()
array(['Golden', 'Aurora', 'Boulder', 'Denver', 'Lakewood'], dtype=object)
df['Location'].value_counts().plot(kind='bar', colormap=cm.Paired)
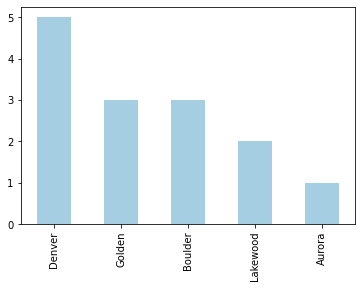
Perfect!
Another useful piece of information is weather data. That’s in a separate tab in the excel file, so we’ll export that as a csv and load it up.
weather_df = pd.read_csv('./versions/Weather - v1.csv')
weather_df = weather_df.fillna(method='ffill')
weather_df
Pandas has a join method, so we can connect that to our original dataset…
df.join(weather_df, how='outer')
Not so much.
Pandas needs an index to join on, and to actually match content, the index in both dataframes needs to be identical.
So another round of hand-editing, and we have a dataset we can join on.
weather_df = pd.read_csv('./versions/Weather - v2.csv', index_col='Date')
weather_df
df = df.join(weather_df)
df
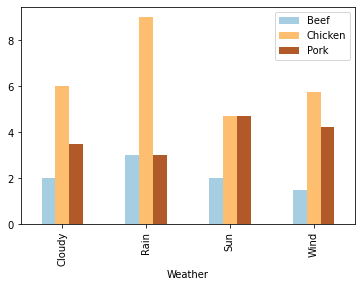
Now that we’ve joined both datasets, we can group the first one by weather and see on average how many tacos we sell on sunny days.
df[['Beef', 'Chicken', 'Pork', 'Weather']].groupby('Weather').mean().plot(kind='bar', colormap=cm.Paired)
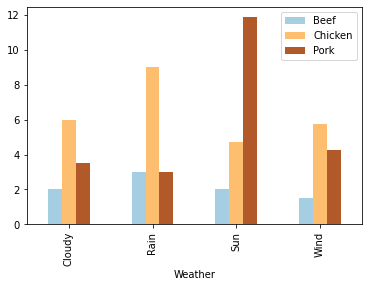
Remember that weird spike in pork sales on the 13th we noticed earlier?
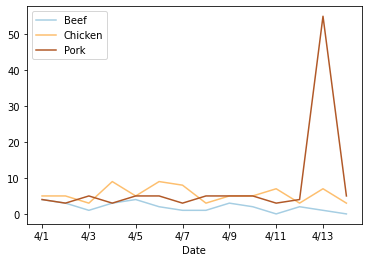
We can obviously see that there’s something wrong with our data here, but with some datasets, the data engineer working with the data may not have the domain knowledge or context to recognize outliers. In situations like that, it’s really helpful to provide them with a “codebook”, or description of the dataset. In it, whoever put together the initial dataset can describe their data - the “weather” column should have labels like “sun”, “rain”, etc; pork sales should be an integer (no half tacos!) between 0 and 15; and so on.
You can ignore the code in the next cell, it’s just going through and automatically generating a codebook off of our dataset.
df['Weather'] = df['Weather'].astype("category")
df['Location'] = df['Location'].astype("category")
desc_df = pd.DataFrame(index=['count', 'dtype', 'unique', 'top', 'freq', 'mean', 'std', 'min', '25%', '50%', '75%', 'max'])
cats_df = pd.DataFrame()
labels = set()
for col in df.columns:
df_col = df[col].describe().to_frame().astype('object')
df_col.loc['dtype'] = df[col].dtype.name
labels = labels | set(df_col.index.values)
desc_df = desc_df.join(df_col, how='left')
if df[col].dtype.name == 'category':
df_cats = df[col].dtype.categories\
.to_frame(name=col)\
.reset_index(drop=True)
cats_df = cats_df.join(df_cats, how='outer')
desc_df = desc_df.append(cats_df)
desc_df.to_csv('./codebook.csv')
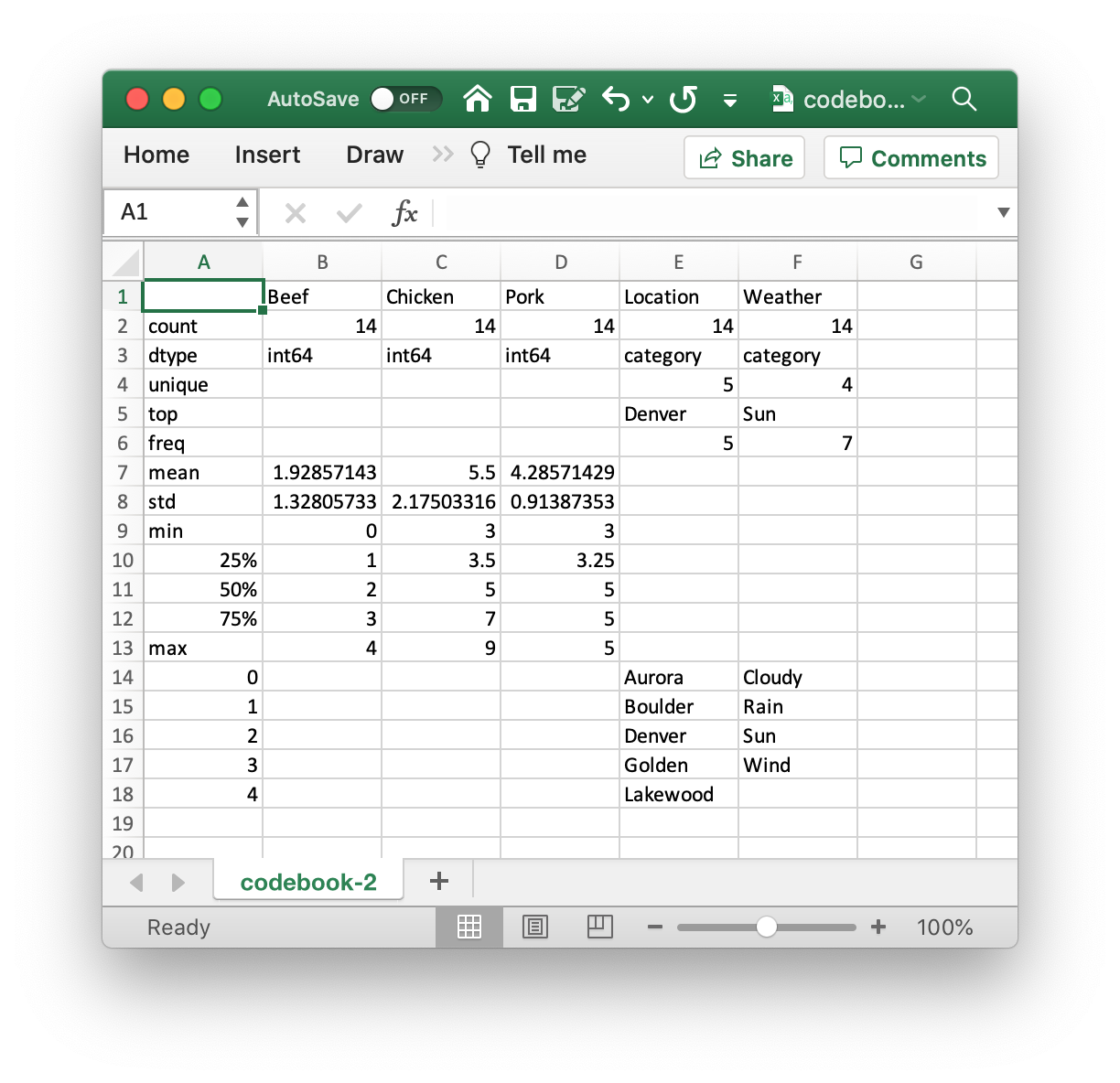
The resulting codebook looks like this:
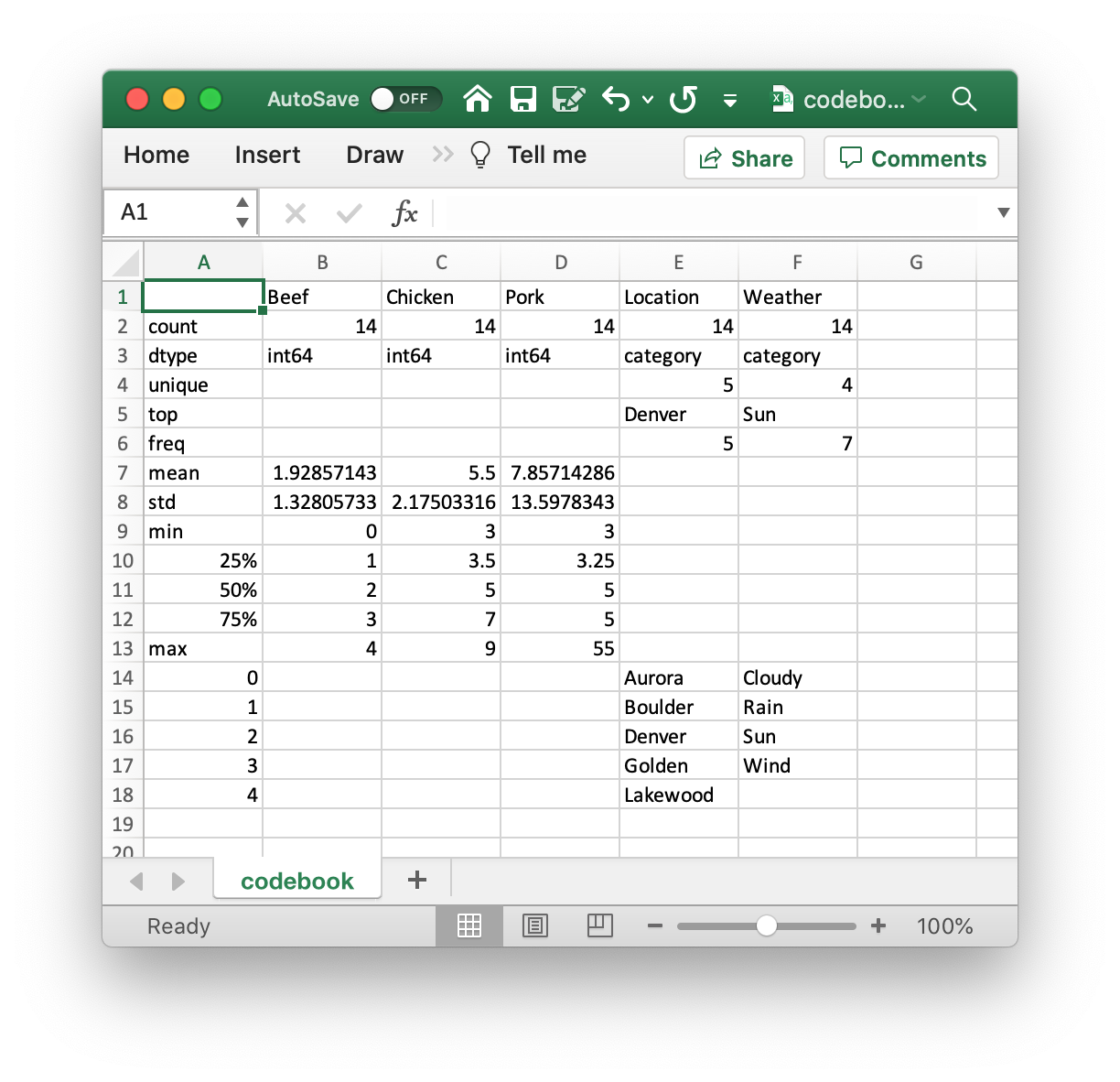
Can you see the problem? The maximum value in the “Pork” column is 55. Compared to both “Beef” and “Chicken” sales, but also the 75th percentile of “Pork” sales, that seems way out of wack.
If we go back to the original data, we can see a pretty obvious typo of “55” instead of “5”.
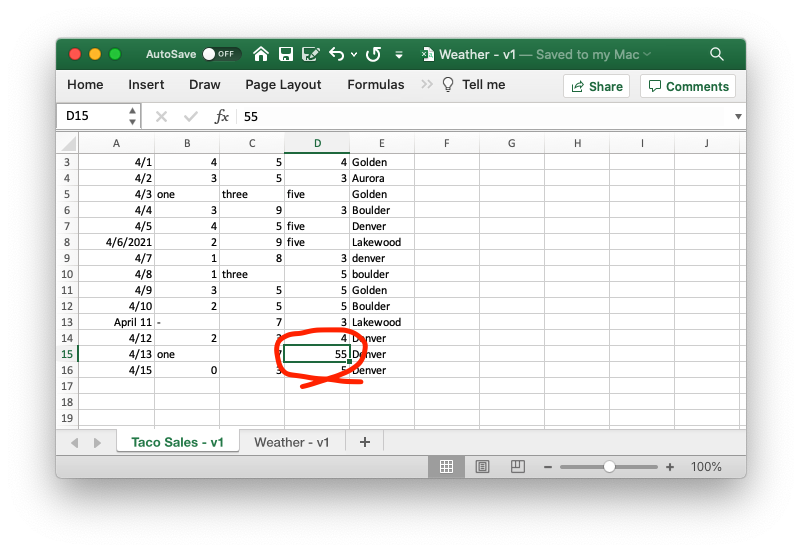
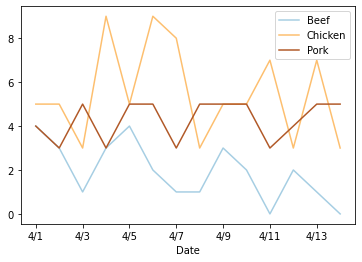
Once we fix that, we can reload all of our data, join the two sheets together again, and get graphs and codebooks like we’d expect.
df = pd.read_csv('./versions/Taco Sales - v6.csv', index_col='Date')
weather_df = pd.read_csv('./versions/Weather - v2.csv', index_col='Date')
df = df.join(weather_df)
df
df[['Beef', 'Chicken', 'Pork']].plot(colormap=cm.Paired)
df[['Beef', 'Chicken', 'Pork', 'Weather']].groupby('Weather').mean().plot(kind='bar', colormap=cm.Paired)
df['Weather'] = df['Weather'].astype("category")
df['Location'] = df['Location'].astype("category")
desc_df = pd.DataFrame(index=['count', 'dtype', 'unique', 'top', 'freq', 'mean', 'std', 'min', '25%', '50%', '75%', 'max'])
cats_df = pd.DataFrame()
labels = set()
for col in df.columns:
df_col = df[col].describe().to_frame().astype('object')
df_col.loc['dtype'] = df[col].dtype.name
labels = labels | set(df_col.index.values)
desc_df = desc_df.join(df_col, how='left')
if df[col].dtype.name == 'category':
df_cats = df[col].dtype.categories\
.to_frame(name=col)\
.reset_index(drop=True)
cats_df = cats_df.join(df_cats, how='outer')
desc_df = desc_df.append(cats_df)
desc_df.to_csv('./codebook-2.csv')
Going back to the question in our title, hopefully, you have a better sense of why the software developer you’re working with keeps complaining about nitpicky little things like spaces and inconsistent capitalization. It’s not that they’re driven by overwhelming OCD, but that the tools that they use are.
In many cases, there are programmatic solutions to the problems I’ve described. In almost all of them, though, some kinds of assumptions must be made that could potentially result in data loss (try ignoring capitalization in “ExpertsExchange” and see if the meaning changes).
So, to keep everyone happy, a couple of tips for cleanly formated data:
- Use a plaintext format, like CSV, instead of the default XLSX output.
- Use a consistent date format. ISO 8601 is a fantastic one, but in most cases, consistency is the most important thing.
- Make sure to trim leading and trailing spaces. They can be hard to spot in excel, but that’s where a well-made codebook can come in handy.
- Provide a codebook! They’re super helpful for spotting your own errors, but are also useful for someone who doesn’t know the data as well as you do to get themselves familiar with your dataset and know what to expect.
Reference files and codebooks can be found here.